






1. INTRODUCTION
Automatic wood species identification systems have enabled fast and accurate identification of wood species outside of specialized laboratories with well-trained experts on wood species identification. Previously most of the automated wood species identification systems have used pipelines relying on hand-tuning segmentation, feature extraction and classification steps for each macroscopic images of the wood surface.
Feature extractors or image descriptors require hand-engineering to obtain optimal features to quantify the content of an image. In general, image content quantification algorithms can be classified into several categories such as encoding color (color moments, color histograms, color correlograms), encoding shape (Hu moments and Zernike moments), encoding texture (Local Binary Pattern and Haralick texture), key point detectors (FAST, Harris, DoG, and so on), local invariant descriptors (SIFT, SURF, BRIEF, ORB, and so on), and Histogram of Oriented Gradients (HOG).
For the past years, many researchers have explored various types of feature extractors for wood identification: hue, saturation, value, contrast, angular second moment, sum of variances, long run emphasis, fractal dimension, and wavelet horizontal energy proportion (Yu et al., 2009), color-based features (Peng, 2013), texture- based features such as Gabor filters, Gray Level Co-occurrence Matrices (GLCM), Local Binary Patterns (LBP), Completed Local Binary Pattern (CLBP), Local Phase Quantization (LPQ), Basic Grey Level Aura Matrix (BGLAM), Improved Basic Grey Level Aura Matrix (I-BGLAM), Statistical Properties of Pores Distribution (SPPD), Mask Matching Image (MMI), Coiflet Discrete Wavelet Transform (DWT), the Markovian, spectral, and illumination invariant textural features, anisotropic diffusion and Local Directional Binary Patterns (LDBP) (Tou et al., 2009a; Tou et al., 2009b; Nasirzadeh et al., 2010; Yusof et al., 2010; Yusof and Rosli, 2013; Kobayashi et al., 2015; Kobayashi et al., 2017; Khalid et al., 2011; Khairuddin et al., 2011, Wang et al., 2013a; Wang et al., 2013b; Yadav et al., 2013; Mohan et al., 2014; Yadav et al., 2014; Martins et al., 2015; Haindl and Vácha, 2015; Zamri et al., 2016; Hiremath and Bhusnurmath, 2017), key point detectors, and local invariant descriptors such as Speeded Up Robust Features (SURF) (Huang et al., 2009) and Scale-Invariant Feature Transform (SIFT) (Hu et al., 2015; Martins et al., 2015). A Kernel-Genetic Algorithm (K-GA) technique was also used for feature selection (Yusof et al., 2013a).
From the extracted feature vectors, researchers used different types of classifiers such as k Nearest-Neighbor (kNN) classifier (Khalid et al., 2011; Khairuddin et al., 2011; Kobayashi et al., 2015; Hu et al., 2015; Hiremath and Bhusnurmath, 2017), Support Vector Machine (SVM) (Martins et al., 2013; Paula Filho et al., 2014; Hu et al., 2015; Zamri et al., 2016), Linear Discriminant Analysis (LDA) classifier (Khalid et al., 2011), a multi-layer neural network based on the popular back propagation (MLBP) algorithm (Yusof et al., 2010; Yusof and Rosli, 2013), Artificial Neural Networks (ANN) (Hu et al., 2015), Multilayer Perceptron Backpropagation Artificial Neural Network (MPB ANN) (Yadav et al., 2013), several WEKA classification algorithms (Yadav et al., 2014), and correlation (Mohan et al., 2014). Sometimes, a pre-classifier such as Fuzzy logic- based pre-classifier (Yusof et al., 2013b) was used to increase classification accuracy. For the same purpose, several studies adapted combinatory strategies such as image segmentation and multiple feature sets (Cavalin et al., 2013; Kapp et al., 2014), a two-level divide-and-conquer classification strategy (Paula Filho et al., 2014), the combination of all classifiers, and different dynamic selection of classifiers (DSC) methods (Martins et al., 2015). Also, an adaptive multi-level approach for combining multiple classifications was applied to forest species recognition (Cavalin et al., 2016).
In these days, the hand-engineering process in the conventional automatic image recognition has been replaced by utilizing Convolutional Neural Networks (CNNs) such as LeNet (Lecun et al., 1998), AlexNet (Krizhevsky et al., 2012), GoogLeNet (Szegedy et al., 2014), VGGNet (Simonyan and Zisserman, 2014), ResNet (He et al., 2016), and so on. The CNNs trained for wood species can extract intrinsic feature representations and classify them correctly. It usually outperforms classifiers built on top of extracted features with a hand-tuning process. A CNN model was developed to recognize Brazilian forest species (macroscopic images for 41 species and microscopic images for 112 species), and resulting accuracy was better than 97% for both datasets (Hafemann et al., 2014).
Utilization of a mobile device like a smartphone is essential to speed up the wood identification process on sites. A smartphone equips with a decent camera can be used as a camera for automatic wood species identification from macroscopic pictures of wood although it is not the best choice for the conventional process of feature extraction tasks. Also, illumination condition is often not appropriate for most of the traditional image recognition tasks. However, deep neural network techniques give a chance to overcome the limitations posed by the conventional feature extraction methods requiring high-quality images under controlled illumination.
In this study, we developed an automatic wood species identification system utilizing CNN models and macroscopic images that were obtained by a smartphone camera. Regarding the accuracy of the automatic wood species identification system, several pipelines based on different CNN models were evaluated for five Korean wood species (cedar, cypress, Korean pine, Korean red pine, and larch).
2. MATERIALS and METHODS
Five Korean softwood species [cedar (Cryptomeria japonica), cypress (Chamaecyparis obtusa), Korean pine (Pinus koraiensis), Korean red pine (Pinus densiflora), and larch (Larix kaempferi)] were under investigation by an automatic wood species identification utilizing CNN techniques. We purchased fifty lumbers of each species of 50 × 100 × 1200 mm3 (thickness × with × length) from several mills participating the National Forestry Cooperative Federation in Korea. The lumbers in each species were from different regions of Korea. 10 ~ 20 specimens of 40 × 50 × 100 mm3 (R × T × L) were cut from each lumber (50 wood samples per species).
We used a smartphone (iPhone 7) to obtain macroscopic pictures of the sawn surfaces of cross sections of the specimen. During image acquisition process, the smartphones placed on a simple frame as a stable support. The camera in an iPhone 7 model has f/1.8 lens and phase detection autofocus function and produces an image of 12 Megapixels. The camera produces a color picture of 3024 × 4032 pixels. The pixel size of the image was 41.7 μm. Only center part of the picture contains an image of wood. The images were vertical shape, and thus only a part of the wood image (1200 × 2400 pixels around the center) was cropped. The total number of the cropped images were 187. Fig. 1.
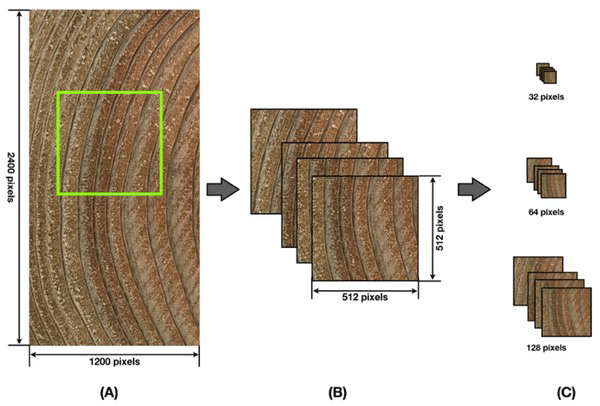
We prepared 16865 images of 512 × 512 pixels by utilizing a sliding window method; 12649 images of all (75%) were used for training and the other 4216 images (25%) for validation. Table 1 listed the number of images for each species. Also, we separately prepared an “External Validation Set (EVS)” for determination of the accuracy of the automated wood species identification. The images in the EVS were not overlapped those in the training and testing sets. The EVS included total 50 images (10 images from each species) of 1200 × 2400 pixels.
| Species | Train | Test | Total |
|---|---|---|---|
| cedar | 2321 | 774 | 3095 |
| cypress | 2565 | 855 | 3420 |
| Korean pine | 2970 | 990 | 3960 |
| Korean red pine | 2295 | 765 | 3060 |
| Larch | 2498 | 832 | 3330 |
| Total | 12649 | 4216 | 16865 |
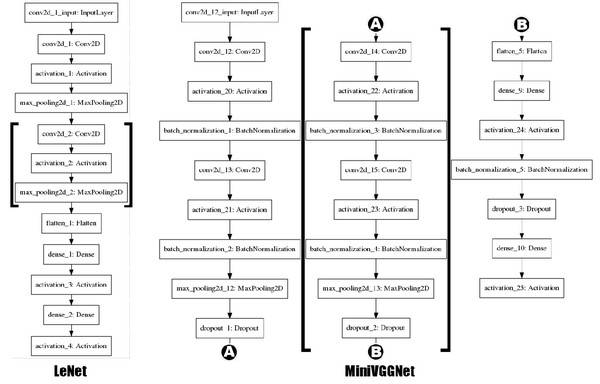
The CNNs are the types of algorithms that can learn appropriate parameters of various image processing operations such as smoothing, sharpening, and edge detection for an input image. The CNNs also have capabilities to automatically learn discriminating filters for detection of low-level structures such as edges and blob-like structures as well as of high-level objection such as faces, cats, dogs, cups, etc. This utilization of the lower-level layers or features to learn high-level features is called the compositionality of CNNs, which is achieved by stacking a specific set of layers purposefully. Building blocks of CNNs are convolution (CONV) layer, activation (ACT) layer, pooling (POOL) layer, fully-connected (FC) layer, batch normalization (BN), and dropout (DROPOUT). Combinations of these building blocks become a CNN architecture for a given task (Table 2 and 3).
LeNet and VGGNet were the base of the models investigated in this study. LeNet architecture is simple with only two convolution layers (Fig. 2 and Table 2). VGGNet is a deep CNN (16 or 19 layers), but we stripped VGGNet down to only with two layers of two convolutional layers to build MiniVGGNet (Fig. 2 and Table 3). We added third and fourth extensive layers into the base models to build LeNet2, LeNet3, MiniVGGNet2, and MiniVGGNet3. For the LeNet-based model, (CONV ⟹ ACT ⟹ POOL) was the extensive layer unit, but for the MiniVGGNet model, (CONV ⟹ ACT ⟹ BN ⟹ CONV ⟹ ACT ⟹ BN ⟹ POOL ⟹ DROPOUT) was the one.
The Stochastic Gradient Descent (SGD) algorithm optimized the model parameters with the learning rate = 0.01. The loss function was binary cross entropy. A number of epochs were 50 with a batch size of 64. Training process used three levels (32, 64, and 128 pixels) of input images. Pixel values of the input images were normalized by 255. A workstation with XEON CPU (28 threads) with 64 GB of memory as well as GPU with 24 GB (NVIDIA Quadro M6000). The operating system was Ubuntu 16.04 LTS with CUDA 8.0, Python 2.7, Tensorflow 1.2 and Keras 2.0.
We evaluate identification performance of the CNNs by utilizing the following equation.
From the EVS (images of 1200 × 2400 pixels), we randomly cropped 100 patches with 512 × 512 pixels. We chose the size of the patch to include wood anatomical features such as growth rings. Each patch was fed into the model generated by utilizing the model architecture described in section 2.3. For each prediction, we examined the classification result whether it is true or false, and then calculated an accuracy of wood species identification by the model.
To utilize macroscopic features of different wood species, we need to make the patch images to include at least several growth rings. We determined the patch size according to the given condition for macroscopic features of all wood species. In the case of the smartphone camera without a zoom factor, the field of view in 512 × 512 pixels was turned out to be a proper size.
3. RESULTS and DISCUSSION
In general, the accuracy of the CNN models was improved by size increase of the input image (Table 4, 5, and 6; Fig. 3). With image size = 32, average accuracies of LeNet, LeNet2, LeNet3, MiniVGGNet, MiniVGGNet2, and MiniVGGNet3 were (72.1, 79.5, 84.2, 41.2, 61.2, and 55.3%), respectively. With patch size = 64 and 128, they increased to (92.5, 95.4, 91.6, 89.8, 91.9, and 89.8%), and (94.1, 97.4, 99.3, 95.2, 97.5, and 97.5%), respectively. The accuracy improvement by the increase of the input image is related to the disappearance of minute details of image content during the resizing process.
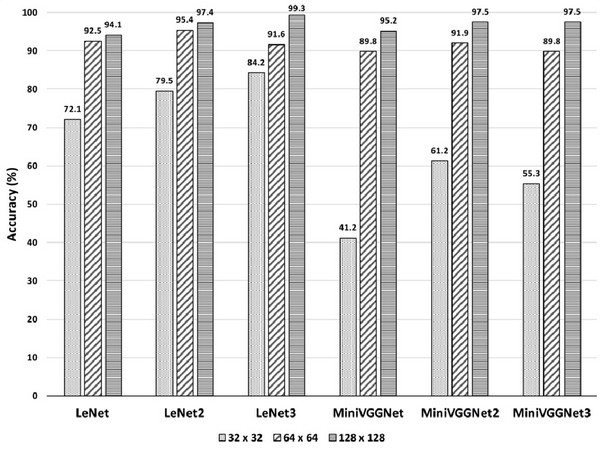
With the addition of layers to the original LeNet and MiniVGGNet, accuracy improvement was not apparent with image size = 32 and 64 (Table 4 and 5). With image size = 128, improvement of accuracy was evident for the LeNet-based model, but not consistent with the MiniVGGNet models (Table 6).
All MiniVGGNet-based models with patch size = 128 showed very high average accuracy, but the standard deviation was greater than 3%. The highest accuracy (99.3 ± 0.7%) was obtained by LeNet3 model with image size = 128. Thus, LeNet3 was considered to be the best CNN model for identification of the five Korean softwood species (Table 6).
There was no clear trend in accuracy improvement related to wood species, but the LeNet-based and MiniVGGNet-based models gave the best identification accuracy for different species. With image size = 128, LeNet3 model showed 100% accuracy for cedar, but MiniVGGNet3 showed 100% accuracy for cypress and Korean red pine (Table 6). While MiniVGGNet3 showed only 90.8% for Korean pine, LeNet3 produced greater than 98% for all other species. Thus, it is clear that LeNet3 was the best species identification CNN model for the five Korean softwoods.
Improvement of identification accuracy according to the size of input images was apparent (Fig. 3). All models showed the lowest accuracy with the smallest image size (32 × 32 pixels). When the images of 512 × 512 pixels were resized into 32 × 32 pixels image, most of the details of the images considered to be disappeared. No distinctive features from the small images were not learned to differentiate the wood species. By the increase of the size of the input image, more features remained. As a result, the identification accuracy was improved. With this fashion, bigger size of input images might improve accuracy more, but computational cost increases. If we collect more images and expand the number of classes for identification, input images might not be loaded into the computer memory. We need to consider computational cost, a number of classes, and a number of images in each class whether the image size needs to be increased further or not. At the moment, the LeNet3 model produced > 98% accuracy for all five species; image size = 128 was considered to be sufficient for the use of this automatic wood species identification with a macroscopic image from a camera in an iPhone 7 smartphone.
Quality of a smartphone camera is a major factor to affect the accuracy of the automatic wood species identification. The image qualities of different smartphone cameras were not investigated in this study, but any smartphone with a decent camera module is expected to obtain images with sufficient quality of macroscopic images from a rough sawn surface of the wood. The illumination condition used in this study was controlled to produce not much of shade, but the image acquisition setup utilized in this study was straightforward to make an auxiliary attachment for a smartphone. With a proper auxiliary attachment for a given smartphone, we can quickly reproduce the quality of macroscopic images.
4. CONCLUSION
In this study, we investigated the use of deep learning techniques to automatically identify wood species of five Korean softwoods (cedar, cypress, Korean pine, Korean red pine, and larch). We built six CNN models (LeNet, LeNet2, LeNet3, MiniVGGNet, MiniVGGNet2, and MiniVGGNet3) and trained the models for the five species. A smartphone camera was used to obtain macroscopic images from rough sawn surfaces of the cross sections of the softwoods.
The experimental results showed that the best accuracy (99.3%) was achieved by LeNet3 model trained with macroscopic images captured by iPhone 7 camera. The MiniVGGNet3 model produced 97.5% accuracy on the same dataset of the softwoods, but the standard deviation was much larger (3.6%) than that of LeNet3 model (0.7%).
We demonstrated higher than 99% accuracy of wood species identification with a deep CNN model with four convolutional layers. The result in this study proved that a fast and accurate automatic wood species identification system could be developed by utilizing deep CNN models. The weights produced by the CNN models were small enough to be installed on a mobile device such as a smartphone. Deploying a mobile device with an automatic wood species identification capability can relieve the issues of slow process to obtain an accurate wood species identification due to lack of well-trained field agents, which causes the delay of logistics.